

Leaf-Spine vs Campus Network Design — рассматриваем архитектуру современной сети, какие есть тенденции, куда всё движется и почему.
Весь материал исключительно в разрезе технологий CISCO. Технологии других вендоров будут отличаться.
Classic Campus Network Design
Вспоминаем CCNA. Центровой для CISCO дизайн это CISCO Enterprise Architecture Model. Основа этого дизайна модульность. Достигается путём разбиения сети на модули, где каждый модуль выполняет свои функции и предоставляет свои сервисы.
Преимущества:
- Чёткое структурирование;
- Улучшенная производительность;
- Упрощение дизайна сети;
- Если в каком-то модуле возникла проблема, то другие модули от неё изолированы;
- Упрощённый траблшутинг;
- Отличная масштабируемость.
Иерархический дизайн сети (или дизайн кампусной сети) в своём классическом виде, то есть без всяких улучшений, характерен для конца 90х начала 2000х годов. Это один из модулей CISCO Enterprise Architecture:
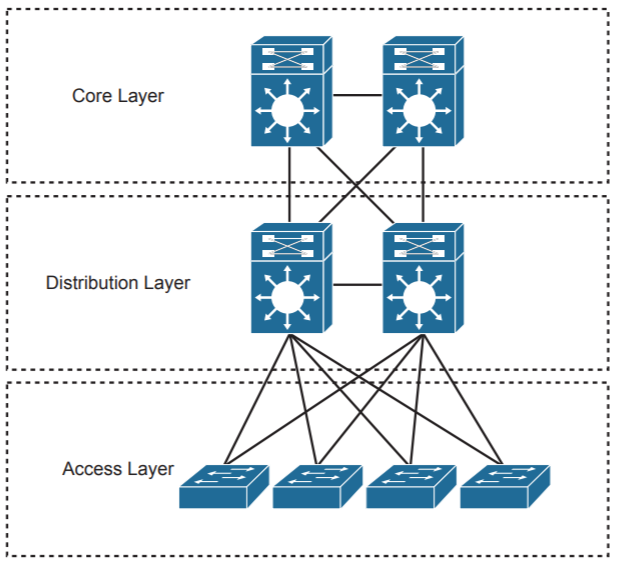
Известная всем трехуровневая модель. Предназначена она для офисного здания или группы зданий. Модель разбита на уровни, значит те же самые плюсы что и для CISCO Enterprise Architecture в целом. Вроде бы все радости жизни, но это не так, далее будет понятно почему.
Особенности уровней
Быстро пробежимся по особенностям уровней для классического дизайна. Чтобы понимать где именно могут возникнуть узкие места и проблемы.
Access Layer или Network Edge
Служит только для подключения конечных пользователей и их оборудования.
PCs, ноутбуки, принтеры. Не используется для подключения серверов, удалённых сотрудников, VPN-туннелей и WAN-каналов. Для этого есть отдельные модули Enterprise Architecture.
Коммутаторы уровня доступа (классический вариант CISCO 29XX) не соединяются между собой. Почему? Такой линк будет fulltime заблокирован STP, так как корневой мост это один из коммутаторов распределения. Кроме того ACLs и другие сервисы расположены на коммутаторах уровня распределения. Значит весь трафик между коммутаторами доступа по соображениям безопасности и правильного функционирования сети должен проходить через коммутаторы уровня распределения.
На уровне доступа происходит начальная маркировка пакетов для QoS. Также здесь осуществляется контроль подключения устройств с помощью Port Security или продвинутого 802.1X, MAC Authentication Bypass (MAB).
Distribution Layer
Точка агрегации для коммутаторов уровня доступа. Самый нагруженный с точки зрения сервисов и функций уровень.
Через этот уровень проходит граница L2 и L3 сети. В сторону уровня доступа STP, в сторону уровня ядра L3 линки и суммаризация маршрутов. Чтобы такая суммаризация стала возможна, адресное пространство нужно изначально правильно разбить. То есть адресация для группы VLANs на уровне доступа должна быть из одного крупного диапазона адресов, тогда этот диапазон и станет суммарным маршрутом на уровне распределения.
Кроме этого на уровне распределения используются: ACLs как для VLANs, так и в строну ядра, правила обработки очередей QoS. В качестве протокола маршрутизации OSPF, реже проприетарный EIGRP.
Коммутаторы уровня распределения ставятся исключительно парами для отказоустойчивости и соединяются между собой линком L2 (обычно CISCO 3000 серии). Если уровень ядра не используется (свёрнутое ядро, two-tier model) и есть несколько пар коммутаторов распределения, то все они соединяются по принципу “всё на всё” (полносвязное соединение, Full Mesh). Тут уже L3 линки, внутри пары L2 линк так и остаётся, он нужен для правильной работы STP.
У каждой пары коммутаторов распределения свой L2 домен. И поэтому VLANs не растягиваются между разными парами. Но это и не нужно. Предполагается что пара коммутаторов распределения обслуживает одно здание. Разные здания, разные пары коммутаторов распределения, разные L2 домены, разные VLANs.
Уровень ядра или Backbone
Служит как быстрый транспорт и точка подключения других модулей.
Когда пар коммутаторов уровня распределения много, то полносвязная связь между ними становится слишком сложной. Возрастает количество дорогостоящих высокоскоростных оптических портов (и дорогостоящих оптических трасс соответственно) для такого соединения на каждом коммутаторе уровня распределения.
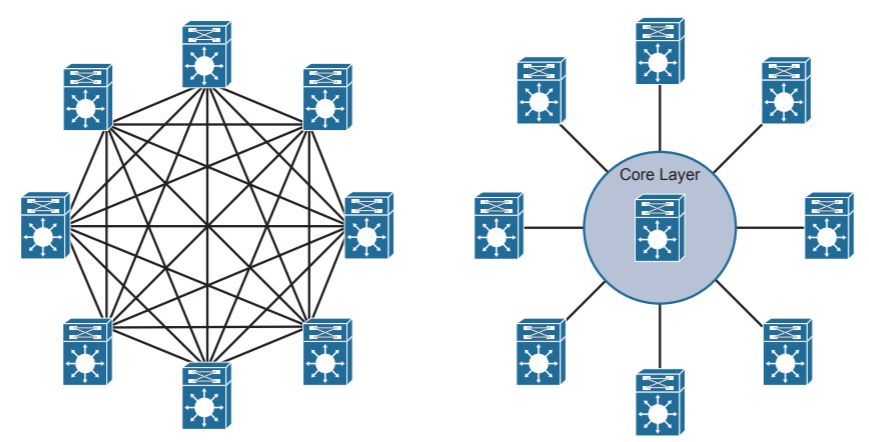
Чтобы избежать усложнения дизайна сети и возможно даже снизить стоимость вводится дополнительный уровень (three-tier model). Это уровень ядра. Использование уровня ядра обосновано уже при наличии трех пар коммутаторов уровня распределения.
Первая функция: быстрый транспорт. При этом ACLs не используются. Нужно лишь быстро перекачать трафик между коммутаторами агрегации.
Модули CISCO Enterprise Architecture
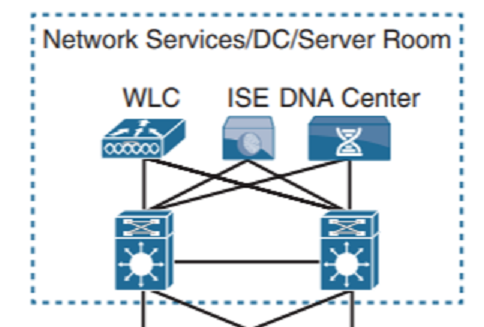
Вторая функция: сюда подключаются другие модули. К ним относятся: модуль Server Farm (или ЦОД предприятия), модуль Network Services (WLCs, ISE, Cisco TelePresence Manager, CUCM) и совокупность модулей Enterprise Edge. В последний обычно входят модули: Internet Edge, DMZ, удаленный доступ RA (Remote Access), VPN — отдельные L3 VPN-каналы, WAN Edge.
Надо понимать, что такое деление на вот такие модули — полностью условное. Устройство модулей (физическая топология), их количество, может различаться в зависимости от профиля/размера организации, от используемого оборудования и сервисов. Они могут быть по-разному скомпонованы. Например, Internet Edge может быть слит с DMZ, RA слит с VPN, а могут быть все отдельно (в том числе, через одного или разных ISP). Другой пример, не использует компания WAN каналы (выделенные линии, провайдерские MPLS VPN), так как они дорогостоящие, значит WAN Edge отсутствует. Отсутствовать может любой модуль, так как количество вариаций дизайна сети практически безгранично. Допустим, офис (маленький/средний/большой разницы нет), отсутствует модуль Server Farm, так как в этом офисе вообще нет серверов. В нём же отсутствует модуль Internet Edge, так как выход в интернет осуществляется централизовано, через центральный офис.
Все эти модули требуют высокой пропускной способности (по крайней мере Server Farm), что усложняет дизайн сети при использовании свёрнутого ядра. Опять нужно подключение ко всем коммутаторам распределения, опять избыток используемых линков и портов. А когда есть уровень ядра всё сразу становится проще.
Уровень ядра это обычно два специализированных коммутатора (CISCO 4000 серии), один из которых основной, а второй резервный. Также может использоваться распределение нагрузки между коммутаторами. Маршрутизаторы не используются в силу своей программной природы, значительно уступая по быстродействию. Коммутаторы уровня ядра соединены между собой одним или несколькими линками L3. Все коммутаторы уровня распределения подключены к каждому коммутатору ядра.
Проблемы классической кампусной сети
Технологии развиваются стремительно и в какой-то момент оказалось что Classic Campus Network Design не справляется со своими задачами. Почему так получилось?
- Произошло укрупнение сетей;
Количество приложений и сервисов выросло значительно. Появилась виртуализация, на одном хосте виртуализации может быть несколько десятков виртуальных серверов. Количество пользовательских и конечных устройств тоже выросло. IP-телефоны, Wi-Fi точки доступа, планшеты, смартфоны, устройства для проведения презентаций и другое. В начале 2000х такого просто не существовало. Настройка доступа от всех пользовательских устройств до серверов и приложений (ACLs, QoS, PBR, NAT, маршрутизация) стала объёмной каждодневной рутиной. И делать это всё надо вручную в CLI многочисленных устройств. Возможно что-то можно автоматизировать, но такая автоматизация дробина в море.
Какие ещё проблемы есть у классической кампусной модели сети?
- STP. Биг трабл.
Почему все так не любят STP? Во-первых, потому что этот протокол сам по себе небыстрый для схождения. И если перезагружается/меняется рутовый коммутатор, то провал в работоспособности сети может достигать десятков секунд. Кластерные сервера (особенно БД-SQL), связки серверов Front-End/Back-End, сервера с подвязанной шарой — теряют работоспособность. Их надо заранее гасить/переносить или потом уже восстанавливать руками.
Во-вторых, STP развесистый, включает в себя много стандартов, все эти стандарты разные, по-разному работают и настраиваются. Значит на стыке двух разных стандартов STP вероятно вылезут какие-то проблемы. Возможно сразу, может быть через какое-то время. И как выяснилось, практически никто не знает, что делать в такой ситуации. Потому что не любят учить материалы по STP и не понимают досконально работу протокола.
В-третьих, STP значительно утилизирует CPU коммутатора при схождении. Помимо этого есть перманентная утилизация CPU, памяти и пропускной способности на отправку BPDU каждые 2 секунды, на расчёт и хранение топологии STP.
В четвёртых, STP блокирует линки. Он был придуман чтобы блокировать избыточные линки. Значит, в любом случае, при использовании STP теряется пропускная способность, которой всегда не хватает. Это самое главное.
Потребовались новые подходы. И они быстро нашлись. Всего их четыре, три относительно простых и дин сложный.
Layer 2 Access Loop-Free Design
Начинаем улучшать нашу кампусную сеть. Самый первый и очень хороший вариант это запереть каждую VLAN внутри одного коммутатора доступа, затем меняем линк между коммутаторами распределения с L2 на L3 и петли нет. Нет петли, STP не нужен. От коммутатора доступа до обоих коммутаторов распределения линки не блокируются (на рисунке слева). Но обычная потребность компании как раз чтобы VLANs были растянуты между коммутаторами доступа, тогда блокирования линков не избежать (на рисунке справа):
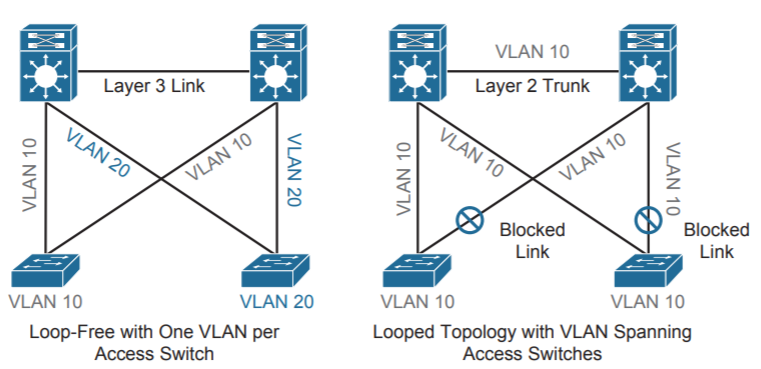
Зачем растягивать VLANs между коммутаторами? У нас на уровне доступа VLAN это какой-то отдел, подразделение, рабочая группа. Для IP адресов из этой VLAN действуют единые правила обработки трафика на коммутаторах распределения. При этом отдел может быть рассредоточен в разных локациях по зданию и физически подключить всех в один коммутатор доступа не представляется возможным. Или же сотрудников отдела много и портов на одном коммутаторе не хватает.
Возвращаемся к Layer 2 Access Loop-Free Design, допустим мы используем HSRP или VRRP на коммутаторах распределения. Хотя оба линка от коммутатора доступа до коммутаторов распределения не блокируются, утилизируется только один, так как HSRP/VRRP не умеют распределять нагрузку. Поэтому вместе с Layer 2 Access Loop-Free Design рекомендуется использовать GLBP.
Layer 3 Access design
Двигаемся дальше, что ещё можно придумать? Был создан подход с L3 Routed Access Layer. Все линки переводятся в L3, домен L2 при этом сжимается. Теперь внутри каждого коммутатора доступа свой L2 домен:
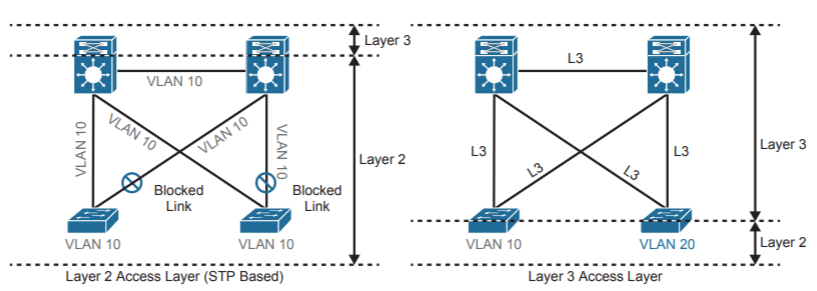
Преимущества:
- Быстрое схождение сети (на основе протокола маршрутизации вместо STP);
- Утилизация всех линков от уровня доступа к уровню распределения с использованием Equal Сost Multi Path (ECMP) дизайна;
- FHRP больше не нужен как обеспечение функции резервирования шлюза по умолчанию для VLANs;
- STP в своей классической реализации исключается из сети (он по прежнему необходим внутри каждого коммутатора доступа в качестве LoopBack Detection);
- Раз нет STP, то не нужно копаться в его потрохах. Простой траблшутинг с помощью ping и traceroute.
Теперь недостатки. Опять та же самая проблема как и с Layer 2 Access Loop-Free Design, не можем растягивать VLANs на несколько коммутаторов доступа. И из-за этого сегментация, правила на коммутаторах распределения становятся более сложными. Кроме того нужны другие коммутаторы для уровня доступа, умеющие L3 в достаточном объёме (дороже по стоимости).
И хотя Layer 3 Access суперское решение, оно опять подойдёт не для всех компаний. Что же делать? Вариантов много, один из них растягивать VLANs с помощью VXLAN поверх L3. Для этого коммутаторы должны уметь VXLAN, а это дорого. Посмотрим что есть ещё.
Simplified Campus Design
Следующее улучшение кампусной сети, Simplified Campus Design основано на физическом (StackWise) и виртуальном стекировании коммутаторов (VSS) при активном использовании EtherChannel. Стекирование, кластеризация, EtherChannel могут быть применены на любом уровне кампусной сети, обеспечивая следующие преимущества:
- Упрощение дизайна сети, вместо двух устройств на уровне распределения используется одно логическое, без потери отказоустойчивости;
- Не нужны протоколы FHRP, так как шлюз по умолчанию опять же одно логическое устройство;
- Снижается зависимость от STP, потому что линки внутри EtherChannel не блокируются;
- Повышается пропускная способность по той же причине;
- Упрощается траблшутинг из-за упрощения дизайна;
- Повышается сходимость сети, скорость работы EtherChannel при упавшем линке гораздо выше скорости работы STP;
- Попроще с растягиванием VLANs, по крайней мере внутри одного стека доступа проблем нет. Плотность портов при этом достаточная для любого отдела.
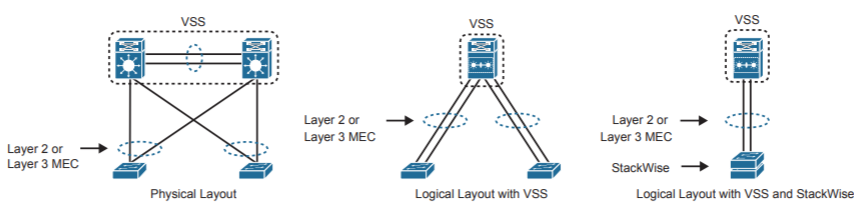
VSS (или vPC в случае нексусов) применяется и на уровне ядра. Simplified Campus Design может рассматриваться как компромиссное решение между L3 Access и Classic L2 Access.
Вот такие три метода-подхода. Остался четвёртый, о нём подробнее.
Cisco Digital Network Architecture
Наконец последняя, самая передовая разработка для кампусной сети использует Cisco Digital Network Architecture (DNA). Скажу своими словами: DNA это комплекс программно-аппаратных средств виртуализации, автоматизации и аналитики сети.
Где применяется? Центровое решение тут Software-Defined Access Design (SD-Access, SDA). Есть и другие решения, в частности SD-WAN, но они не имеют отношения к кампусной сети, поэтому будем рассматривать только SDA.
Что это и как устроено? Здесь основные понятия: обычная наша физическая underlay сеть, поверх которой работает виртуальная overlay сеть. Overlay ещё часто называют fabric.
Fabric is a term used to describe an overlay that represents the logical topology.
Фабрика построена на инкапсуляции, в начальной точке данные запаковываются, в конечной распаковываются. И в общем-то неважно какие физические устройства будут промежуточными, сколько будет этих устройств. Для фабрики они полностью прозрачные.
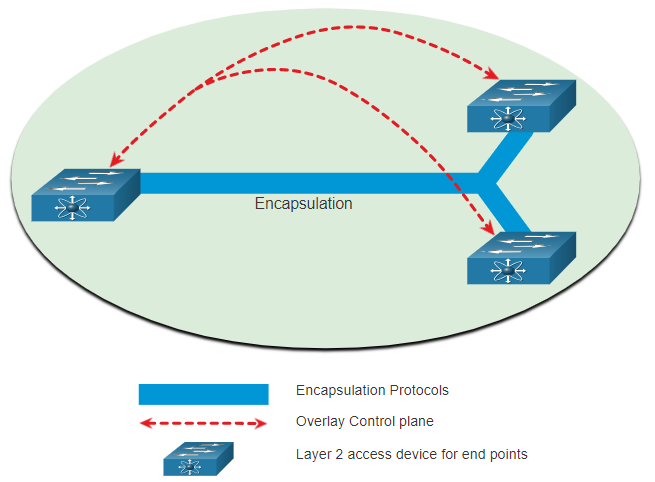
Зачем нужно? Здесь две основных причины:
- Настройка сети вручную часто ведет к ошибкам, человеческий фактор;
- Как уже говорилось, при непрерывном росте сети однотипные операции по настройке в консолях множества устройств становятся рутиной.
Необходим штат спецов, которые смогут эффективно лабать в консоли. Это определённая квалификация, а значит и расходы на зарплату. Использование DNA сильно упрощает жизнь и штат сотрудников.
В чём профит? Мы настраиваем только overlay, делаем это легко и просто с помощью графического интерфейса управления (GUI). При этом изменения как в overlay, так и в underlay настраиваются автоматически. Надо учитывать что в overlay устройств меньше, так как часть устройств underlay сети скрыта. Поэтому настройка дополнительно упрощается.
Что ещё нового? DNA является сосредоточием новых протоколов:
- Протокол LISP, позволяющий оверлей уровня 3, кардинально упрощает маршрутизацию и сокращает размеры таблиц маршрутизации;
- VXLAN позволяет оверлей уровня 2 и 3, обеспечивает свободное перемещение пользовательских устройств в сети, при этом они остаются внутри своей VLAN со своим IP;
- CISCO TrustSec осуществляет отбор групп пользователей и устройств для ACLs, QoS, PBR и VRF на основе специального тега вместо IPv4/IPv6, MAC (использует VXLAN как транспорт);
- Протокол SXP для экспорта политик на основе тега TrustSec во внешние сети.
SDA
Из чего состоит? Из Campus Fabric и Cisco DNA Center. Где контроллер DNA Center представляет собой единую для фабрики точку настройки, управления и траблшутинга через DNA Center GUI.
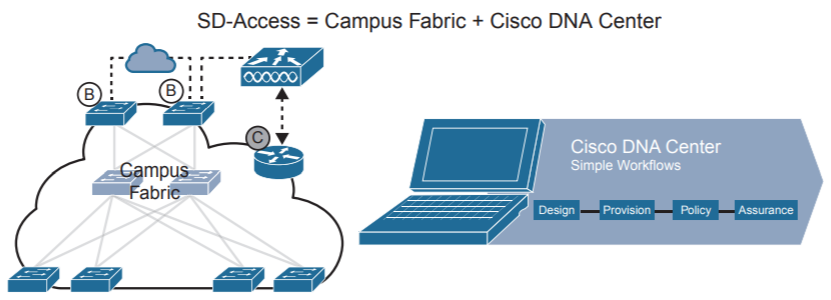
То есть если у нас есть кампусная фабрика и мы ей как-то управляем, в основном вручную, где-то через скрипты, то это только фабрика. Как только добавили автоматизацию — контроллер DNA Center и появилось средство для управления DNA Center GUI, это уже SDA.
Надо учитывать что не просто так взяли и добавили, железки underlay сети. Их версии прошивок должны быть совместимы с DNA. Зависит от релиза DNA Center. При этом LISP здесь Control Plane протокол, а VXLAN соответственно Data Plane. И понятное дело что железки должны уметь эти протоколы. По крайней мере те, которые занимаются инкапсуляцией/деинкапсуляцией.
Какое оборудование? Поддерживается широкая линейка оборудования: свичи, маршрутизаторы как физические так и виртуальные, беспроводные контроллеры и точки доступа. Контроллеры сети здесь DNA Center и обязательно CISCO ISE. Контроллер DNA Center сделан на основе специализированного сервера (DNA Center Appliance), на который заливается ПО от CISCO. Насколько мне известно, DNA Center в виде VM пока официально не существует.
Что “под капотом” SDA, какая архитектура, какие протоколы? Сеть underlay это всё та же трёхуровневая модель, с L3 Routed Access с IS-IS в качестве IGP. И хотя SDA поддерживает модель с underlay сетью настраиваемой вручную (в целях совместимости, для поддержи legacy устройств или устройств других производителей; а также для ручной кастомизации дизайна underlay под специфические задачи, включая L2 дизайн с STP, хотя последний строго не рекомендуется), мы эту модель во внимание принимать не будем. Она весьма странная: при сопоставимых (высоких) затратах теряются все плюсы от сквозной автоматизации.
Где место самого DNA Center Appliance? Обычно это модуль Network Services вместе с остальными управляющими железками. Устанавливается DNA Center в вариантах standalone или cluster.
For more information on SD-Access design and deployment, please refer to the Cisco Validated Design (CVD) guide.
Практика с DNA Center
Где всё это можно посмотреть/пощупать? Конечно же на на DevNet: Technologies-Networking-CISCO DNA Center Platform. Там Sandbox/Learning Labs. Сам DNA Center доступен через GUI, через API (Postman и другое). Youtube в помощь.
И тут мы плавно подошли к рассмотрению Leaf-Spine архитектуры.
Leaf-Spine Design
Рассматривать будем на примере CISCO ACI (Application-Centric Infrastructure).
Что здесь? Всё та же самая фабрика, всё та же самая единая точка настройки, управления и траблшутинга в виде CISCO APIC (Application Policy Infrastructure Controller) с GUI. Всё тот же специализированный сервер от CISCO под APIC. Довольно дорогостоящий. И их нужно несколько штук для отказоустойчивости (2, 2+1,..).
Какие отличия от Campus Network Design? Прежде всего у архитектуры Leaf-Spine другое назначение, она предначена конкретно для модуля серверной фермы предприятия (или же для ЦОД). Есть конечно же и другие, включая ну оочень экзотические применения архитектуры Leaf-Spine. Вот пример что можно сделать с обычным молотком.
Какие проблемы если не использовать автоматизацию (ACI)?
- Стандартных 4000+ VLANs легко может не хватить для большого ЦОД, учитывая овер-зашкаливающее количество виртуальных серверов;
- Проблема с размерами CAM Table на коммутаторах, MAC’ов столько, что они просто не помещаются в таблицы;
- STP блокирует линки;
- Нет ECMP;
- Перемещение серверов сложно и требует замены IP;
- Кроме этого какие-то сервера могут нести на себе сервисы/приложения, для которых нужна L2 связность (обмен сообщениями или броадкастом, или nonrouted мультикастом). Дизайн сети дополнительно усложняется, перемещение серверов тоже.
Особенности дизайна

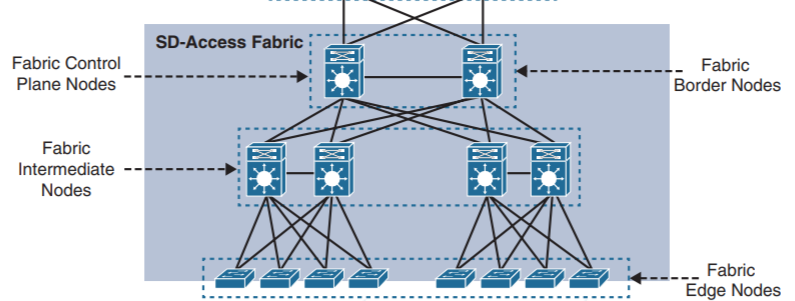
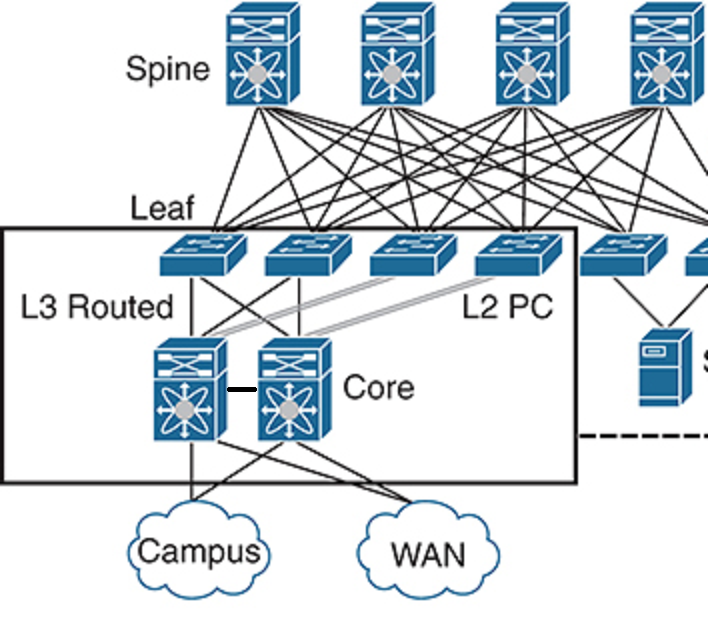
Дизайн из двух уровней, как видно из названия: Leaf и Spine. Всё оборудование, включая сервера и APIC, подключается к коммутаторам Leaf. Аналогично уровню доступа в архитектуре кампусной сети. Коммутаторы Spine обеспечивают передачу данных между коммутаторами Leaf. Аналогично свёрнутому ядру, но всё же основная функция Spine это быстрая пересылка (backbone of the ACI fabric). Коммутаторов Spine значительно меньше, они более производительные.
Коммутатор Leaf подключается ко всем коммутаторам Spine. Важно: коммутаторы Leaf не соединяются между собой, коммутаторы Spine не соединяются между собой также. Все линки L3. Поэтому любые два коммутатора Leaf находятся ровно в двух хопах друг от друга.
Именно поэтому Leaf-Spine не подходит как замена кампусной сети. Припоминаем, там 2 коммутатора распределения на здание и соединяется всё через ядро. А тут как вы будете соединять все Leaf со всеми Spine? Зданий может быть много. Придуманы конечно изменения дизайна, когда Spine разделяется на 2 уровня, Super Spine.., но тут больше вопросов.
Сколько нужно свичей? Минимум два Spine для отказоустойчивости. Максимум столько, сколько сможем. Здесь важна и стоимость, и плотность портов, и количество Leaf коммутаторов.
Масштабируемость? Если нам нужно подключить больше оборудования, добавляем Leaf коммутатор. Нужно больше пропускной способности, добавляем коммутатор Spine.
А как же функции уровня распределения? Что с безопасностью? Всё очень хорошо. Весь трафик по умолчанию запрещён. Чтобы трафик ходил его нужно в явном виде разрешить в APIC GUI.
Последний тут момент, как Spine-Leaf подключается к остальной сети? Ведь наша Server Farm не в воздухе висит. Если кратко, то через Leaf коммутаторы. Они называются Border Leaf.
Практика с ACI
Где посмотреть ACI? Опять DevNet: Technologies-Networking-Automation and Analytics-ACI
Второй вариант, там будет доступен пробный урок (Free Trial Version) и в этом уроке аж целых три интерактивных лабы.
Минусы Leaf-Spine
При добавлении коммутатора Leaf, уходит по одному порту на каждом коммутаторе Spine. И столько портов на самом коммутаторе Leaf, сколько всего Spine коммутаторов. При добавлении коммутатора Spine аналогично.
Поэтому главный минус конкретно этой архитектуры — высокий расход дорогостоящих портов на саму архитектуру. И коммутаторы нужны не какие-нибудь, а Nexus 9000 серии со специальной прошивкой. Масштабирование упирается в плотность портов на коммутаторах. Из-за этого старшие коммутаторы в линейке для ACI, просто монстры портов (Nexus 95XX).
Второй минус общий для автоматизированных решений — высокие начальные вложения на приобретения всей этой красоты (конкретно здесь Nexus + APIC).
В статьях про Leaf-Spine как минус иногда приводится большое количество проводов. Поржал.

Плюсы автоматизированных решений
Плюсы ACI практически полностью аналогичны автоматизированному решению для кампусной сети (SDA):
- Быстрое начальное авто-развёртывание сети с использованием best-practice;
- Быстрое схождение underlay на основе IS-IS;
- Высокая утилизация линков с использованием ECMP в IS-IS;
- STP выпилен из underlay в пользу ECMP;
- Неограниченное число VLANs на основе технологии VXLAN;
- VLANs растягиваются между коммутаторами сети опять же из-за VXLAN;
- Простая работа с VRF;
- Широкие возможности настройки политик (безопасности, QoS);
- Управление сетью через единую точку автоматизации — GUI контроллера;
- Простая настройка, в подавляющем большинстве случаев не нужно вникать в детали используемых технологий и протоколов, контроллер автоматически настроит как overlay, так и underlay;
- Хорошая аналитика, контроллер сам расскажет что плохо и требует внимания;
- Экономия денег после внедрения. Инженера на удаленке со знанием GUI контроллера вполне достаточно чтобы настраивать, мониторить и траблшутить достаточно крупную сеть. Ну и техник непосредственно на месте. По крайней мере так в теории, на практике бывает, что куча спецов вместе с TAC не могут решить проблему. Однако по мере дальнейшей обкатки технологии такие случаи будут всё реже.
Как строятся сети
Наконец-то можно поговорить об общем подходе к построению сетей.
- Определяется тип трафика;
Его характер, структура, объём. Всё это изучается и тщательно прорабатывается.
- Выбирается архитектура сети;
Не с потолка, не потому что модная и у всех на слуху. Архитектура сети выбирается конкретно под тип трафика. Или другими словами, тип трафика определяет архитектуру сети. Только так и никак иначе.
- Выбираются сетевые протоколы;
В общем-то сетевые протоколы во многом определяются архитектурой сети. Но также тут есть некая вариативность, поле для выбора. И можно разного напридумывать. При этом всегда надо учитывать, что любое задействование дополнительных протоколов, ведёт к усложнению. А значит увеличивает количество потенциальных сбоев, ошибок в настройке, рутинных операций по администрированию сети. Всё-таки боле правильный путь здесь, идти по пути упрощения. То есть снижать количество используемых сетевых протоколов.
- Последним шагом выбирается оборудование.
Оно должно поддерживать выбранные протоколы, функционально и по производительности соответствовать архитектуре сети. То есть и под архитектуру, и под протоколы. Прикручивание дополнительных протоколов значительно удорожает стоимость конечного железа. Опять приходим к желательному упрощению при выборе протоколов.
Leaf-Spine vs Campus Network Design
Добрались наконец до заголовка статьи. Как постарался показать никакого противопоставления нет.
Есть горизонтальный трафик ЦОД между серверами. Под него архитектура Leaf-Spine. Leaf-Spine служит основой сети ЦОД (либо же входит в Enterprise Architecture в качестве модуля Server Farm). С впечатляющей отказоустойчивостью и ECMP. Есть вертикальный трафик кампусной сети, пользователи ходят в интернет и к cервисам. Под него трёхуровневая модель, с улучшениями или без них, в классическом виде.
Два дизайна для абсолютно разных целей. Эти дизайны существуют параллельно друг другу, не пресекаясь, занимая каждый свою нишу.
Не нужно “натягивать сову на глобус” и в каком-то виде пытаться прикрутить Leaf-Spine к кампусной сети. Там нет горизонтального трафика, основные преимущества Leaf-Spine не будут использованы. В свою очередь, трёхуровневая модель не вытянет огромные нагрузки по трафику в ЦОД.
Пример
Не углубляясь. Допустим, решили использовать Leaf-Spine в кампусной сети. 🙂 Логично использовать протокол VXLAN для растягивания VLANs без STP. Будьте любезны даже пользовательские коммутаторы купить с поддержкой VXLAN. И тут оказывается, что каждый такой коммутатор стоит как самолёт. Минимально CISCO Catalyst 9000 серии, новенькие. А одобрят вам такие бюджеты? Одобрят, хорошо. Но только в огромном количестве организаций сетевой уровень доступа, повод для экономии. И даже сейчас, туда ставят какие-нибудь 2960X.
Можно пойти дальше, купить ещё более крутые цодовские коммутаторы. И тут засада, на них нету PoE. Никто никогда не думал, что на этих коммутаторах потребуется PoE. А как вы будете подключать телефоны с питанием по PoE, точки доступа? Ещё покупать БП, инжекторы PoE? Далее, на этих коммутаторах нет поддержки протоколов для пользователей. Так как изначально не пользовательский коммутатор. Нет 802.1X, нет протоколов безопасности (спуфингов, гардов, секьюритей). Что дальше?
Даже если Leaf-Spine хорошо заработает в кампусной сети. Не знаю, не видел такого нигде. Вопрос о целесообразности стоит тут ребром.
В разрезе CISCO
Что касается CISCO, то современные технологии кампусной сети (говорю про SDA) и современные технологии Leaf-Spine (говорю про ACI) “слиты из одной пробирки”.
Cisco DNA Center is the successor to Cisco APIC-EM. Cisco DNA Center provides new features to automate the management of network devices, assure the health of your network, and integrate with external systems.
Тут справедливо отметить, что APIC контроллер только для ACI, а APIC-EM для Enterprise LAN/WAN. То есть штуки это разные. Но принцип тот же самый, есть “умная железка” в сети, контроллер, который забирает на себя основные операции.
Заключение и выводы
Написать эту статью меня сподвигло прочтение “Про архитектуру Leaf Spine”. В качестве задания на усвоение материала предлагаю прочесть этот труд, найти все ошибки и отметить упущенные важные моменты. Бо́льшую часть материала я передрал взял из ENCOR 350-401 Official Cert Guide. Если я в чём-то ошибся, то велкам в комментарии. Поправь, добавь, здесь это приветствуется. На этом всё, до встречи в новых статьях.
Вопрос скорее не в том, как соотносятся разные дизайны сети, а то что сеть стремительно эволюционирует в сторону виртуализации и автоматизации. Это важнее. Внедряются новые технологии, старые дизайны сети активно дорабатываются с учётом новых требований.
Приглашаю поделиться мнением в Tелеграм канал
статье 4 года, как ваше мнение по поводу того, что было написано тогда?
Что изменилось:
1. Cisco глобально сдает позиции в кампусных сетях, неприменимость spine-leaf в кампусе выглядит как натягивание совы на глобус, поскольку кампусные коммутаторы Cisco просто не умеют ни чего из того что нужно для построения сетей underlay-overlay
2. Cisco DNA мертворожденная технология, очевидно что ни чего крупного на этом не построишь, оно конечно работать будет, но цена вопроса да и в целом адекватность решения крайне сомнительная
3. Конечно если есть цель строить только на cisco и поставить условие что так будет всегда, то можно такое сотворить, но Cisco сначала сдала позиции в сфере NGFW, потом wifi, роутеры с sdwan бредовая технология, ну и далее кампусные коммутаторы технологически отстали от всего мира, ACI тоже отжившая технология
Спасибо, Сергей, за интересный комментарий. Есть энтерпрайз, есть дата-центр. Откуда берётся архитектура? Из типа трафика. А технологии подбираются под архитектуру. Оборудование, конечный этап, создаётся как под архитектуру, так и под технологии.
Подробнее. Дата-центр, преобладающий трафик горизонтальный (между серверами). Архитектура однозначно лиф-спайн. Кампусная архитектура не походит под такой вид трафика. Технологии MP-BGP, BFD, ECMP, туннелирование (VXLAN, Geneve, SRv6), высокая степь автоматизации (NETCONF/RESTCONF и не только). Оборудование, умеющее это всё. С максимальной скоростью коммутации, с коммитом, под CI/CD.
Теперь энтерпрайз. Трафик вертикальный. Лиф-спайн не походит для такого трафика. Не потому что кампусные коммутаторы не умеют, вообще не подходит. Никак. Здесь капустная 2/3 уровневая архитектура. Она изначально под кампус. Технологии LACP, STP, OSPF и BGP на ядрах. Супер-высокая скорость переключения не нужна, как и поддержка всех туннельных протоколов. Поэтому кампусные коммутаторы и не умеют сильно в оверлей. Им не нужно уметь. Вредно даже. Так как вызовет неизбежное удорожание. А значит снизит конкурентоспособность. Изменилось это за 4 года? Нет. Изменится в ближайшие 10? Тоже нет. Это другого плана оборудование, куда более простое, чем дата-центровое.
Теперь про циско. NGFW понятно не циска. В дата-центре не циско. Так получилось. Зато циско клепает отличные решения для энтрепрайза. Каталисты 9000, 9000 Wireless Family. С устройствами идёт DNA лицуха, которая много чего умеет. А пары нексусов 9000 вполне хватит для небольшой серверной фермы внутри кампуса. Какая отсталость? Кто превзошёл их в этом на момент? Хотелось бы услышать. 🙂 Не понял также по поводу “роутеры с sdwan бредовая технология”. А что не бредовая? Посмотрим Gartner Magic Quadrant для SD-WAN (последний за сентябрь 24), там циска в лидерах. Gartner не аргумент получается? А то что циска убивает свои хорошие решения феноменальной жадностью, ну это не секрет. Так погиб EIGRP, который мог быть наравне с OSPF по распространённости. DNA Center/SD-Access сюда же.