

Troubleshooting часть 1 — углубляемся в ping и traceroute, разбираем малоизвестные факты об этих популярных инструментах траблшутинга.
Всем знакомые ping и traceroute. Все их используют и не особо обращают внимание. А что там знать? Ведь команды эти крайне простые. Всё ли так просто на самом деле? Проверь себя. Рассказ как всегда в контексте устройств CISCO.
Для начала неплохо будет ознакомиться с базовыми концепциями траблшутинга из курса CCNA. Вот эта запись и там Урок 9.
Traceroute
Сначала traceroute, здесь поинтереснее. Самое первое тут: traceroute может использовать разные протоколы передачи данных и конкретно в CISCO это не ICMP. Да, вот в CISCO так. Здесь UDP, поэтому в настройках расширенного traceroute есть пункт выбора порта. Порт по умолчанию 33434, его можно поменять.
Тем не менее traceroute всё равно задействует ICMP в своей работе. И механизм этой работы такой: пакеты с UDP начинкой отправляются с различным TTL (от 1 до 30). Для первого пакета TTL равен единице, для второго двум и так далее.
На каждом хопе TTL уменьшается на 1 и когда он обнуляется, то устройство где это произошло, отправляет ICMP собщение отправителю о данном событии (ICMP Time Exceeded Message, TEM). Из этого сообщения извлекается информация (IP адрес отправителя) и выводится на экран. Каждый следующий пакет уходит на один хоп дальше. Когда наконец пакет достигает хоста назначения, то оказывается что нет приложения прослушивающего UDP порт, указанный в пакете, и хост отправляет об этом сообщение (ICMP Port Unreachable Message). Всё, трассировка завершена.
Пример
Прямо с домашнего компа, у меня Windows, запустим трассировку на адрес 2.2.2.2 и смотрим в Wireshark. Как не трудно увидеть, начнётся пинг адреса 2.2.2.2, с последовательным увеличением TTL в заголовке IP. Не буду выкладывать картинку, ты сам можешь всё это самостоятельно проверить за пару минут. То есть тут именно ICMP. Как трассировка выглядит на устройстве CISCO, будет далее.
Вывод команды traceroute
Теперь подробнее, обращаю внимание что для ping и traceroute есть одинаковые инфомационные сообщения в выводе, только с разным значением. Разберём и вот эти непонятки проясним.
| Character | Description |
|---|---|
| U | Port unreachable |
| H | Host unreachable |
| N | Network unreachable |
| P | Protocol Unreachable |
| T | Timeout |
| ? | Unknown packet type |
| XX msec | For each node, the round-trip time in milliseconds for the specified number of probes |
| * | The probe timed out |
| A | Administratively prohibited (example access-list) |
| Q | Source quench (destination too busy) |
| I | User interrupted test |
Запомним первые два: “крышечка” U недоступен порт, H недоступен хост.
Параметры команды traceroute
R1# traceroute 192.168.3.1 ? dscp Specify DSCP value in ASCII/Numeric ingress LAN source interface for Ingress numeric display numeric address port specify port number probe specify number of probes per hop source specify source address or name timeout specify time out ttl specify minimum and maximum ttl <cr>
Тут зависит от модели устройства и IOS, может быть и вот так:
D1# traceroute 192.168.3.1 ? <cr>
Или так:
R1# traceroute 192.168.3.1 ? numeric display numeric address port specify port number probe specify number of probes per hop source specify source address or name timeout specify time out ttl specify minimum and maximum ttl <cr>
Описание основных параметров:
- numeric – Displays output only in numeric form instead of trying to resolve by DNS as well;
- port – Allows you to set a different starting port number, which defaults to 33433;
- probe – Allows you to change the default 3 probes per hop;
- source – Allows you to specify a different source address for the probe;
- timeout – Allows you to specify a timeout other than the default of 3 seconds;
- ttl – Allows you to specify a minimum and maximum ttl other than the default 1 and 30
Пример
Расширенная трассировка, адрес 192.168.3.1 находится в двух хопах от нашего роутера R1:
R1# traceroute Protocol [ip]: Target IP address: 192.168.3.1 Ingress traceroute [n]: Source address or interface: Loopback0 DSCP Value [0]: Numeric display [n]: Timeout in seconds [3]: Probe count [3]: Minimum Time to Live [1]: Maximum Time to Live [30]: Port Number [33434]: Loose, Strict, Record, Timestamp, Verbose[none]: Type escape sequence to abort. Tracing the route to 192.168.3.1 VRF info: (vrf in name/id, vrf out name/id) 1 10.10.2.2 1 msec 1 msec 1 msec 2 10.20.3.3 1 msec * 1 msec
Какие здесь моменты? В пункте Source address or interface имя интерфейса нельзя сокращать. Команда traceroute вываливает все свои параметры, не спрашивая нас (для пинга по-другому). Loose, Strict, Record, Timestamp, Verbose рассмотрим в разделе про пинг. Для второй пробы к 10.20.3.3 превышено время ожидания ответа (*).
Debug команды traceroute
Включим дебаг и будем ещё смотреть с помощью Wireshark:
R1# debug ip icmp ICMP packet debugging is on R1# traceroute 192.168.3.1 Type escape sequence to abort. Tracing the route to 192.168.3.1 VRF info: (vrf in name/id, vrf out name/id) 1 10.1.2.2 0 msec 1 msec 0 msec 2 10.2.3.3 1 msec *Jul 26 10:35:21.592: ICMP: time exceeded rcvd from 10.1.2.2 *Jul 26 10:35:21.593: ICMP: time exceeded rcvd from 10.1.2.2 *Jul 26 10:35:21.593: ICMP: time exceeded rcvd from 10.1.2.2 *Jul 26 10:35:21.594: ICMP: dst (10.1.2.1) port unreachable rcv from 10.2.3.3 * 1 msec R1# *Jul 26 10:43:03.744: ICMP: dst (10.1.2.1) port unreachable rcv from 10.2.3.3
Посмотрим пакет в Wireshark, очистим вывод с помощью фильтра:
! ospf && ! cdp && ! loop && ! icmpv6
И теперь смотрим:
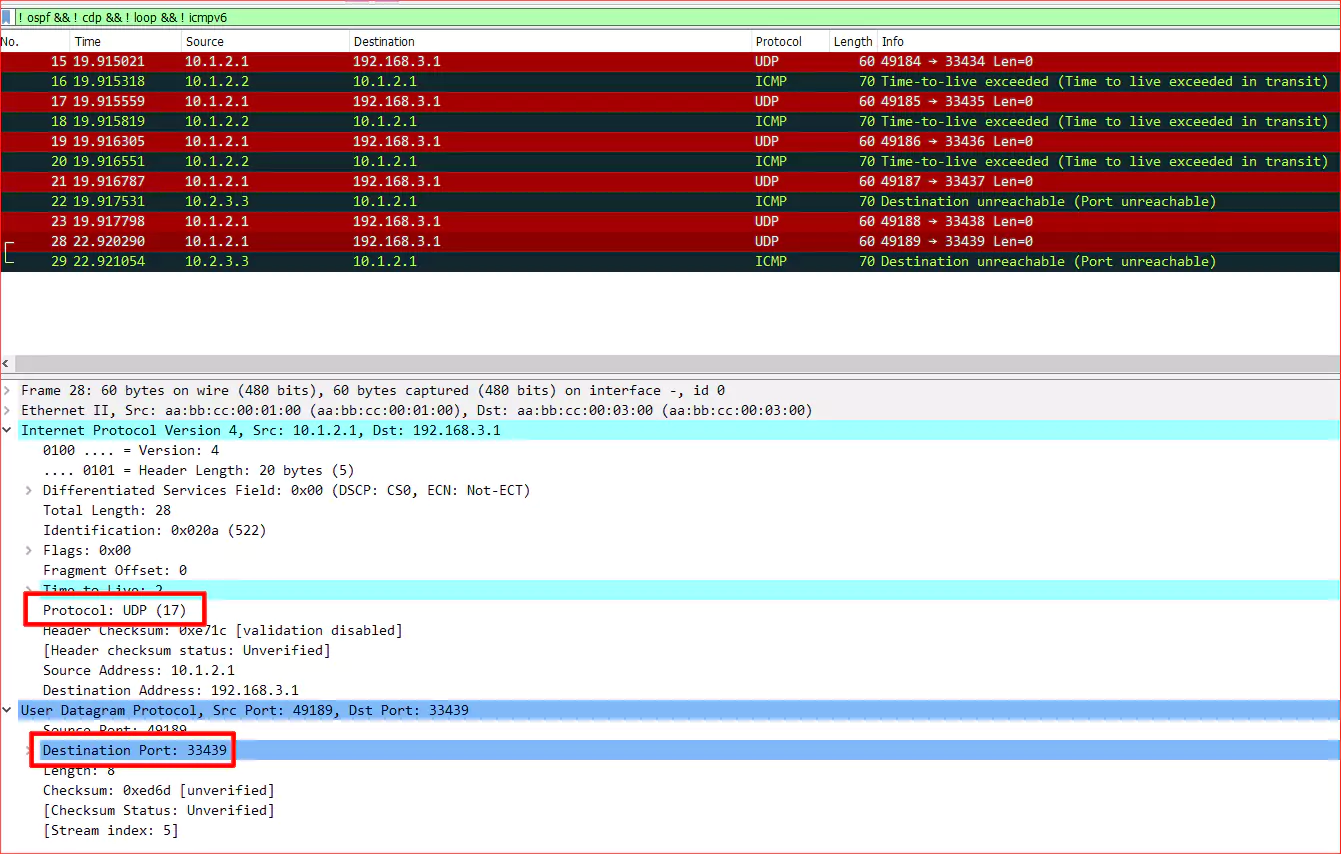
Что мы здесь видим? Было отправлено 6 пакетов, это имено пакеты UDP, в IP заголовке номер протокола 17. Пакеты высылались на порт 33434 для первого пакета и +1 для каждого следующего. Поэтому для шестого 33439. В ответ получено 5 ICMP ответов, 3 Time exceeded, 2 Port unreachable. Все эти ответы видны в дебаге роутера.
Ping
Служит для проверки доступности узла сети. С успешным пингом всё понятно — узел доступен. С неуспешным сложнее, как правило этого недостаточно чтобы сделать какой-то вывод. Требуются дополнительные инструменты и нужно выяснить что там с устройством случилось. Или ничего не случилось. Допустим, узел находится где-то в интернете и администратор закрыл ICMP запросы из интернета. Устройство нормально работает, при этом пропинговать его невозможно.
Внутри локальной сети попроще. Если известно что узел должен пинговаться и вот он не пингуется, значит что-то не в порядке. Опять же нужны дополнительные инструменты. Топ 3 причин неудачного пинга: нет элетричества или сбой ИБП/БП устройства, “добрый самаритянин” выдернул провода (сетевые или электрические) или повредили кабель при ремонтных работах (экскаватор перебил оптику), устройство ушло в ребут (в циклический ребут) или вообще вышло из строя.
Вывод команды ping
| Character | Description |
|---|---|
| ! | The exclamation point indicates receipt of a single reply. The ping successfully reached the destination, the destination replied, and the reply made it back to the originator. This is an ICMP Type 0 message. |
| . | The period indicates that the ping timed out. Normally this indicates that the distant end received the ping, but could not reply for some reason. |
| U | The destination of the ping was unreachable. Although not visible in the router output, there are 16 sub-codes to the unreachable message that describe exactly what was unreachable. |
| M | An intermediate device could not fragment the packet, and so could not forward it. |
| ? | Unknown packet received. |
| & | Packet lifetime exceeded. |
Для ping и traceroute U в выводе имеет разное значение, для пинга U то же самое что H для traceroute. Не знаю как сейчас, но раньше CISCO просто обожала на своих экзаменах бомбить вопросами на знание подобных мелочей.
Пример
Пусть роутер R1 не знает о сети 192.168.10.0/24, то есть её нет в его таблице маршрутизации. И нет маршрута по умолчанию, значит R1 не знает куда отсылать пакеты для этой сети. Тут всё ясно, точки и звёздочки:
R1# ping 192.168.10.1 Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.10.1, timeout is 2 seconds: ..... Success rate is 0 percent (0/5) R1# traceroute 192.168.10.1 Type escape sequence to abort. Tracing the route to 192.168.10.1 VRF info: (vrf in name/id, vrf out name/id) 1 * * * 2 * * * - вывод прерван
Теперь добавим на R1 маршрут по умолчанию, указывающий на IP адрес роутера R2 (адрес следующего перехода). Роутер R2 также не знает о сети 192.168.10.0/24. R1 будет отправлять пакеты на R2 и ждать ответа от R2:
R1# ping 192.168.10.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 192.168.10.1, timeout is 2 seconds:
U.U.U
Success rate is 0 percent (0/5)
R1# traceroute 192.168.10.1
Type escape sequence to abort.
Tracing the route to 192.168.10.1
VRF info: (vrf in name/id, vrf out name/id)
1 10.10.2.2 0 msec 0 msec 0 msec
2 10.10.2.2 !H !H !H
R1#
Теперь поподробнее что же такое unreachable. Если поднимем на R2 ещё дополнительный интерфейс и назначим ему 192.168.10.2/24, то интерфейс UP и таблице маршрутизации появится связанный маршрут:
192.168.10.0/24 is variably subnetted, 2 subnets, 2 masks
C 192.168.10.0/24 is directly connected, Ethernet0/1
L 192.168.10.2/32 is directly connected, Ethernet0/1
Снова запустим ping и traceroute к 192.168.10.1 с R1. Снова будут точки и звёздочки, таймаут. Другими словами, unreachable — это когда роутер (его адрес будет в строчке вывода traceroute) по пути следования пакета (но не локальный роутер) не знает куда дальше пересылать пакет.
Параметры команды ping
R1# ping 192.168.3.1 ? Extended-data specify extended data pattern data specify data pattern df-bit enable do not fragment bit in IP header dscp Specify DSCP value in ASCII/Numeric ingress LAN source interface for Ingress repeat specify repeat count size specify datagram size source specify source address or name timeout specify timeout interval tos specify type of service value validate validate reply data <cr>
Опять же набор параметров может отличаться, основные параметры:
- data/extended-data – By default, the payload of a ping is simply 0xABCD. The data (16 bits) and extended-data (32 bits) options allow you to specify something else. A potential use for this could be looking for payload corruption occurring between two endpoints;
- df-bit – Tells intermediate routers not to fragment the ping. This is commonly used with the size option to test a path for a specific MTU value;
- dscp – Sets a particular Differentiated Services Code Point value. The dscp value is used in Quality of Service, so this option allows you to probe basic QoS compliance through the network;
- ingress – Allows you to specify an ingress interface;
- repeat – By default, ping will send 5 packets. This option allows you to specify how many packets to send. This can be useful to test load balancing and other packet-stream situations;
- size – Allows you specify something other than the default 100-byte packet size. This is commonly used to path MTU validation. It could also be used in combination with the repeat option to keep the transmitting interface busy for a longer period of time;
- source – Allows you to specify a source address or interface. By default, the address of the outbound interface used to route to the destination will be used as the source address. Setting the source manually helps to verify full reachability;
- timeout – Sets the timeout value for each packet to something other than the default of 2 seconds. This option would most likely be used in very slow or very large networks;
- tos – Sets the Type of Service value to something other than the default of 0. This is similar to DSCP but for older methods of service assurance;
- validate – Enables the option to validate each reply
Пример
Расширенный ping:
R1# ping Protocol [ip]: Target IP address: 192.168.3.1 Repeat count [5]: Datagram size [100]: Timeout in seconds [2]: Extended commands [n]: Sweep range of sizes [n]: Type escape sequence to abort. Sending 5, 100-byte ICMP Echos to 192.168.3.1, timeout is 2 seconds: !!!!! Success rate is 100 percent (5/5), round-trip min/avg/max = 2/4/5 ms
Если мы принудительно не включим расширенные команды, то они и недоступны, в отличие от traceroute. Sweep range of sizes будет увеличивать размер пакета от начального значения до конечного с указанным шагом.
...
Sweep range of sizes [n]: y
Sweep min size [36]:
Sweep max size [18024]:
Sweep interval [1]:
Type escape sequence to abort.
Sending 89945, [36..18024]-byte ICMP Echos to 192.168.3.1, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!...
Success rate is 100 percent (705/705), round-trip min/avg/max = 1/5/7 ms
Прервал выполение команды (для этого есть удобная комбинация клавиш Ctrl-Shift-6). Можно использовать Sweep range для проверки MTU (при установленном бите DF в расширенных командах). Ну и собственно сами расширенные команды:
... Extended commands [n]: y Source address or interface: Type of service [0]: Set DF bit in IP header? [no]: Validate reply data? [no]: Data pattern [0xABCD]: Loose, Strict, Record, Timestamp, Verbose[none]: Sweep range of sizes [n]: ...
Тут подробнее про Loose, Strict, Record, Timestamp, Verbose.
- Loose –
Short for Loose Source Route, this option allows you (the source) to influence the path the ping takes by specifying the address(es) of the hop(s) you want the packet to go through. These are suggestions to the router, so if there is a better path, the router may use it; - Strict –
Short for Strict Source Route, this option allows you to mandate the exact path you want the ping to take. Intermediate devices must follow the next hop(s) specified until the destination is reached or there are no more next-hop addresses specified; - Record – This option causes the address of up to nine intermediary hops to be recorded and returned to the originating host. This option records not only the hops along the way to the destination, but the hops in the return path as well;
- Timestamp – Used to measure roundtrip time to particular hosts
На мой взгляд самое полезное здесь это Record, поможет выявить ассиметричный роутинг. Недостаток, пишет всего 9 хопов.
Debug команды ping
R1# debug ip icmp ICMP packet debugging is on R1# ping Protocol [ip]: Target IP address: 192.168.3.1 Repeat count [5]: 1 Datagram size [100]: Timeout in seconds [2]: Extended commands [n]: Sweep range of sizes [n]: Type escape sequence to abort. Sending 1, 100-byte ICMP Echos to 192.168.3.1, timeout is 2 seconds: ! Success rate is 100 percent (1/1), round-trip min/avg/max = 7/7/7 ms R1# *Jul 26 12:08:08.592: ICMP: echo reply sent, src 192.168.1.1, dst 192.168.1.1, topology BASE, dscp 0 topoid 0 *Jul 26 12:08:08.593: ICMP: echo reply rcvd, src 192.168.1.1, dst 192.168.1.1, topology BASE, dscp 0 topoid 0
Для сокращения вывода использовал один пакет. Мы один запрос отправили, один ответ получили. Смотрим Wireshark:

Ходовой вопрос на собеседованиях: для пинга какой порт используется? Никакой. Почему? Чтобы был порт, должен быть заголовок транспортного уровня (TCP/UDP). Для ICMP такого заголовка просто нет в пакете, ICMP цепляется непосредственно к IP заголовку. При этом в IP заголовке номер протокола 1. Самые ходовые протоколы, на собеседовании бывает спрашивают:
1 - ICMP 2 - IGMP 6 - TCP 17 - UDP 50 - ESP 51 - AH
Список номеров всех протоколов тут. Ну вот, надеюсь что-то полезное рассказал. Не стал специально переводить описание к параметрам, так как лучше прочитать в оригинале, чем мой неточный перевод. Кому сложно в оригинале, переводчик в помощь. А вообще пора учить английский.
Сетевые инструменты
Пару слов про полезные утилиты. Как уже сказал, пинг не является достаточным инструментом проверки доступности.
Paping
Пользователь обычно жалуется, что у него не подключается приложение к удалённому серверу. Сервер работоспособен, нужный порт на нём открыт. И тут два связанных вопроса:
- Как выяснить где проблема: в самом приложении, его настройках, сертификатах или именно в сетевой доступности удалённого хоста?
- Как проверить отсутствие блокировок со стороны FWs по пути следования пакета?
Здесь на помощь приходит утилита paping. Её создателю нужно вручить медаль сетевого администрирования. Синтаксис прост:
paping.exe ip_хоста -p порт

Когда paping показывает доступность порта, значит пакет не блокируется FWs. Если конечный хост находится в интернете, его можно просканировать онлайн-сканером, но paping позволяет проверять и локальные ресурсы.
Кроме paping можно использовать клиент telnet, для него страдает наглядность работы и генерируется малое число пакетов. Ещё для Windows команды powershell:
Test-NetConnection ip_хоста -Port порт tnc ip_хоста -port порт
Наглядность работы лучше, чем у telnet, но пакетов генерится так же мало. Конечно на FW в логе ты ставишь фильтры и видишь пакеты даже когда их мало, но удобно работать с логом, если пакетов проходит много. В общем, paping на мой взгляд the best choice.
А что с Linux? Здесь опять же telnet:
# yum install telnet # telnet ip_хоста порт
Или утилита nc:
# yum install nc # nc -z -v ip_хоста порт
MTR/WinMTR
Вторая мега-полезная утилита. Для Windows WinMTR, а для Linux MTR. Позволяет определить на каком именно хопе происходят потери пакета, на каком хопе большая задержка передачи. Она предельно простая, но интерпретировать результаты нужно правильно.
Вот интересная ситуация:
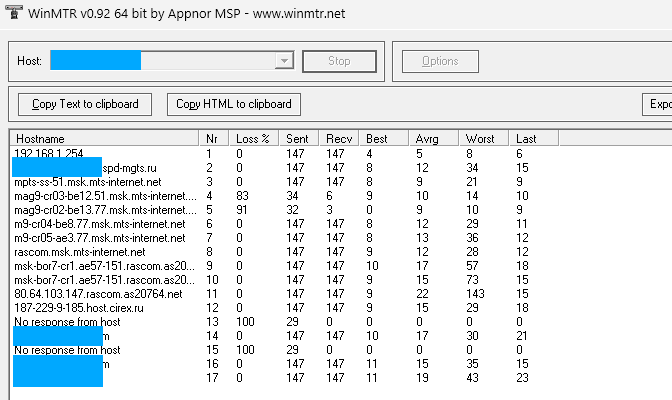
Есть тут потери пакетов? Нет, нету. Почему? Потому что на последний хоп отправлено 147 пакетов и получено от него 147. Хопы со 100% потерей понятная ситуация: сами маршрутизаторы закрыты для ответов по ICMP, но транзитный ICMP трафик пропускается при этом нормально.
Интереснее хопы 4 и 5. Что это? На них установлена политика предельного рейта для отдельных видов трафика, предназначенных самому маршрутизатору. Транзитный трафик опять же не режется. Подробнее тут.
Что тогда является признаком потерь? Когда потери начинаются с определённого хопа и для оставшихся хопов они такие же или растут. Кроме этого необходимо смотреть на задержки Avrg (средняя) и Worst (наибольшая). Если они большие, могут достигать 3000 ms (3 sec), то дело плохо. Даже при отсутствии потерь в этом случае нормальной работы не будет.
Какие сетевые задержки считаются нормой? По мнению CISCO не более 150 ms.
| Диапазон в миллисекундах | Описание |
|---|---|
| 0-150 | Приемлемо для большинства пользовательских приложений. |
| 150-400 | Допустимо при условии, что администраторы осведомлены о времени передачи и его влиянии на качество передачи в пользовательских приложениях. |
| Более 400 | Неприемлемо для общих целей планирования сетей. Однако признается, что в некоторых исключительных случаях этот предел может превышаться. |
Кроме этого (взято тут, если доступ остался):
Эти рекомендации адресованы национальным органам управления связью. Поэтому они накладывают более строгие ограничения, чем те, которые обычно применяются в частных сетях передачи речи. Когда местоположение и коммерческие потребности конечных пользователей хорошо известны проектировщику сети, более высокое значение задержки может оказаться приемлемым. Для частных сетей задержка 200 мс является приемлемой задержкой, а задержка в 250 мс представляет предельное значение.
На сегодня всё, успехов в траблшутинге!